Basics of MPI¶
Programming distributed memory parallel computers happens through message passing. In this lecture we give basic examples of using the Message Passing Interface, in C or Python.
One Single Program Executed by all Nodes¶
A parallel program is a collection of concurrent processes. A process (also called a job or task) is a sequence of instructions. Usually, there is a 1-to-1 map between processes and processors. If there are more processes than processors, then processes are executed in a time sharing environment. We use the SPMD model: Single Program, Multiple Data. Every node executes the same program. Every node has a unique identification number (id) — the root node has number zero — and code can be executed depending on the id. In a manager/worker model, the root node is the manager, the other nodes are workers.
The letters MPI stands for Message Passing Interface. MPI is a standard specification for interprocess communication for which several implementations exist. When programming in C, we include the header
#include <mpi.h>
to use the functionality of MPI.
Open MPI is an open source implementation
of all features of MPI-2.
In this lecture we use MPI in simple interactive programs, e.g.:
as mpicc and mpirun are available on laptop computers.
Our first parallel program is mpi_hello_world.
We use a makefile to compile, and then run with 3 processes.
Instead of mpirun -np 3 we can also use mpiexec -n 3.
$ make mpi_hello_world
mpicc mpi_hello_world.c -o /tmp/mpi_hello_world
$ mpirun -np 3 /tmp/mpi_hello_world
Hello world from processor 0 out of 3.
Hello world from processor 1 out of 3.
Hello world from processor 2 out of 3.
$
To pass arguments to the MCA modules
(MCA stands for Modular Component Architecture)
we can call mpirun -np (or mpiexec -n)
with the option --mca such as
mpirun --mca btl tcp,self -np 4 /tmp/mpi_hello_world
MCA modules have direct impact on MPI programs because they allow tunable parameters to be set at run time, such as * which BTL communication device driver to use, * what parameters to pass to that BTL, etc. Note: BTL = Byte Transfer Layer.
The code of the program mpi_hello_world.c
is listed below.
#include <stdio.h>
#include <mpi.h>
int main ( int argc, char *argv[] )
{
int i,p;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&p);
MPI_Comm_rank(MPI_COMM_WORLD,&i);
printf("Hello world from processor %d out of %d.\n",i,p);
MPI_Finalize();
return 0;
}
Initialization, Finalization, and the Universe¶
Let us look at some MPI constructions that are part of any program that uses MPI. Consider the beginning and the end of the program.
#include <mpi.h>
int main ( int argc, char *argv[] )
{
MPI_Init(&argc,&argv);
MPI_Finalize();
return 0;
}
The MPI_Init processes the command line arguments.
The value of argc is the number of arguments at the command line
and argv contains the arguments as strings of characters.
The first argument, argv[0] is the name of the program.
The cleaning up of the environment is done by MPI_Finalize().
MPI_COMM_WORLD is a predefined named constant handle
to refer to the universe of p processors with labels from 0 to \(p-1\).
The number of processors is returned by MPI_Comm_size
and MPI_Comm_rank returns the label of a node.
For example:
int i,p;
MPI_Comm_size(MPI_COMM_WORLD,&p);
MPI_Comm_rank(MPI_COMM_WORLD,&i);
Broadcasting Data¶
Many parallel programs follow a manager/worker model. In a broadcast the same data is sent to all nodes. A broadcast is an example of a collective communication. In a collective communication, all nodes participate in the communication.
As an example, we broadcast an integer. Node with id 0 (manager) prompts for an integer. The integer is broadcasted over the network and the number is sent to all processors in the universe. Every worker node prints the number to screen. The typical application of broadcasting an integer is the broadcast of the dimension of data before sending the data.
The compiling and running of the program goes as follows:
$ make broadcast_integer
mpicc broadcast_integer.c -o /tmp/broadcast_integer
$ mpirun -np 3 /tmp/broadcast_integer
Type an integer number...
123
Node 1 writes the number n = 123.
Node 2 writes the number n = 123.
$
The command MPI_Bcast executes the broadcast.
An example of the MPI_Bcast command:
int n;
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
There are five arguments:
- the address of the element(s) to broadcast;
- the number of elements that will be broadcasted;
- the type of all the elements;
- a message label; and
- the universe.
The full source listing of the program is shown below.
#include <stdio.h>
#include <mpi.h>
void manager ( int* n );
/* code executed by the manager node 0,
* prompts the user for an integer number n */
void worker ( int i, int n );
/* code executed by the i-th worker node,
* who will write the integer number n to screen */
int main ( int argc, char *argv[] )
{
int myid,numbprocs,n;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numbprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if (myid == 0) manager(&n);
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
if (myid != 0) worker(myid,n);
MPI_Finalize();
return 0;
}
void manager ( int* n )
{
printf("Type an integer number... \n");
scanf("%d",n);
}
void worker ( int i, int n )
{
printf("Node %d writes the number n = %d.\n",i,n);
}
Moving Data from Manager to Workers¶
Often we want to broadcast an array of doubles. The situation before broadcasting the dimension $n$ to all nodes on a 4-processor distributed memory computer is shown at the top left of Fig. 17. After broadcasting of the dimension, each node must allocate space to hold as many doubles as the dimension.
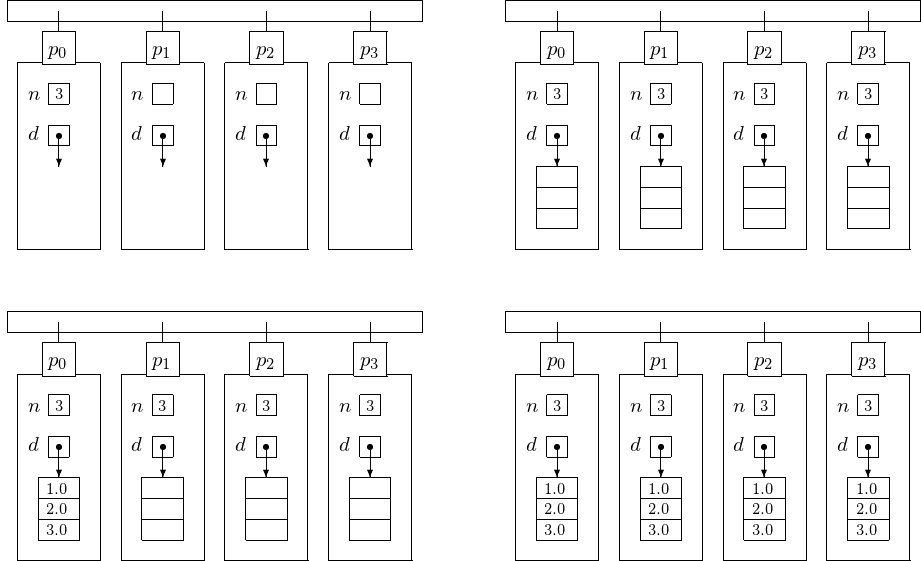
Fig. 17 On the schematic of a a distributed memory 4-processor computer, the top displays the situation before and after the broadcast of the dimension. After the broadcast of the dimension, each worker node allocates space for the array of doubles. The bottom two pictures display the situation before and after the broadcast of the array of doubles.
We go through the code step by step.
First we write the headers and the subroutine declarations.
We include stdlib.h for memory allocation.
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
void define_doubles ( int n, double *d );
/* defines the values of the n doubles in d */
void write_doubles ( int myid, int n, double *d );
/* node with id equal to myid
writes the n doubles in d */
The main function starts by broadcasting the dimension.
int main ( int argc, char *argv[] )
{
int myid,numbprocs,n;
double *data;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numbprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if (myid == 0)
{
printf("Type the dimension ...\n");
scanf("%d",&n);
}
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
The main program continues, allocating memory. It is very important that every node performs the memory allocation.
data = (double*)calloc(n,sizeof(double));
if (myid == 0) define_doubles(n,data);
MPI_Bcast(data,n,MPI_DOUBLE,0,MPI_COMM_WORLD);
if (myid != 0) write_doubles(myid,n,data);
MPI_Finalize();
return 0;
It is good programming practice to separate the code that does not involve any MPI activity in subroutines. The two subroutines are defined below.
void define_doubles ( int n, double *d )
{
int i;
printf("defining %d doubles ...\n", n);
for(i=0; i < n; i++) d[i] = (double)i;
}
void write_doubles ( int myid, int n, double *d )
{
int i;
printf("Node %d writes %d doubles : \n", myid,n);
for(i=0; i < n; i++) printf("%lf\n",d[i]);
}
MPI for Python¶
MPI for Python provides bindings of MPI for Python,
allowing any Python program to exploit multiple processors.
It is available at http://code.google.com/p/mpi4py,
with manual by Lisandro Dalcin: MPI for Python.
The current Release 2.0.0 dates from July 2016.
The object oriented interface follows closely MPI-2 C++ bindings and
supports point-to-point and collective communications
of any pickable Python object,
as well as numpy arrays and builtin bytes, strings.
mpi4py gives
the standard MPI look and feel in Python scripts
to develop parallel programs.
Often, only a small part of the code needs the
efficiency of a compiled language.
Python handles memory, errors, and user interaction.
Our first script is again a hello world, shown below.
from mpi4py import MPI
SIZE = MPI.COMM_WORLD.Get_size()
RANK = MPI.COMM_WORLD.Get_rank()
NAME = MPI.Get_processor_name()
MESSAGE = "Hello from %d of %d on %s." \
% (RANK, SIZE, NAME)
print MESSAGE
Programs that run with MPI are executed with mpiexec.
To run mpi4py_hello_world.py by 3 processes:
$ mpiexec -n 3 python mpi4py_hello_world.py
Hello from 2 of 3 on asterix.local.
Hello from 0 of 3 on asterix.local.
Hello from 1 of 3 on asterix.local.
$
Three Python interpreters are launched. Each interpreter executes the script, printing the hello message.
Let us consider again the basic MPI concepts and commands.
MPI.COMM_WORLD is a predefined intracommunicator.
An intracommunicator is a group of processes.
All processes within an intracommunicator have a unique number.
Methods of the intracommunicator MPI.COMM_WORLD are
Get_size(), which returns the number of processes, and
Get_rank(), which returns rank of executing process.
Even though every process runs the same script,
the test if MPI.COMM_WORLD.Get_rank() == i:
allows to specify particular code for the i-th process.
MPI.Get_processor_name() ``
returns the name of the calling processor.
A collective communication involves every process
in the intracommunicator.
A broadcast is a collective communication in which
one process sends the same data to all processes,
all processes receive the same data.
In ``mpi4py, a broadcast is done with the bcast method.
An example:
$ mpiexec -n 3 python mpi4py_broadcast.py
0 has data {'pi': 3.1415926535897, 'e': 2.7182818284590}
1 has data {'pi': 3.1415926535897, 'e': 2.7182818284590}
2 has data {'pi': 3.1415926535897, 'e': 2.7182818284590}
$
To pass arguments to the MCA modules, we call mpiexec as
mpiexec --mca btl tcp,self -n 3 python mpi4py_broadcast.py.
The script mpi4py_broadcast.py below
performs a broadcast of a Python dictionary.
from mpi4py import MPI
COMM = MPI.COMM_WORLD
RANK = COMM.Get_rank()
if(RANK == 0):
DATA = {'e' : 2.7182818284590451,
'pi' : 3.1415926535897931 }
else:
DATA = None # DATA must be defined
DATA = COMM.bcast(DATA, root=0)
print RANK, 'has data', DATA
Bibliography¶
- L. Dalcin, R. Paz, and M. Storti. MPI for Python. Journal of Parallel and Distributed Computing, 65:1108-1115, 2005.
- M. Snir, S. Otto, S. Huss-Lederman, D. Walker, and J. Dongarra. MPI - The Complete Reference Volume 1, The MPI Core. Massachusetts Institute of Technology, second edition, 1998.
Exercises¶
Visit
http://www.mpi-forum.org/docs/and look at the MPI book, available athttp://www.netlib.org/utk/papers/mpi-book/mpi-book.html.Adjust hello world so that after you type in your name once, when prompted by the manager node, every node salutes you, using the name you typed in.
We measure the wall clock time using
time mpirunin the broadcasting of an array of doubles. To avoid typing in the dimension n, either define n as a constant in the program or redirect the input from a file that contains n. For increasing number of processes and n, investigate how the wall clock time grows.