Counting Words and Pattern Matching¶
Dictionaries are very important data structure. A typical application is build a frequency table. We illustrate this application on a downloaded text.
The builtin module re provides tools to match
strings for regular expressions.
Dictionaries¶
The project Gutenberg at <http://www.gutenberg.org> is a good source for many texts in the public domain. The free books are available as plain .txt files. As our example we take the 1898 novel of H.C. Wells, the war of the worlds, with its cover in Fig. 14.

Fig. 14 Cover of a book in the public domain.
In our course, we are not reading the book for its literary qualities, but we use the text file to count the frequencies of its words.
In our analysis, we assume we have downloaded the entire text
as a .txt file. If we wanted to download the book line by line,
then we could use the following script:
URL = 'http://www.gutenberg.org/files/36/36.txt'
from urllib.request import urlopen
INFILE = urlopen(URL)
while True:
LINE = INFILE.readline()
if LINE == b'':
print('End of file reached.')
break
print(LINE)
ans = input('Get another line ? ')
if ans != 'y':
break
In processing a text file, we want to answer the following questions:
- How many different words are there in the text?
- What is the frequency ofr each word?
- Given a frequency, how many words occur with this frequency?
- What words occur 100 times or more?
To us, anything separated by one or more spaces is a word.
The analysis on the war of the worlds text yields a total word count of 66,491. There are 13,003 different words. Words used more than 100 times, as in the output of the script:
(4076, ['the'])
...
(119, ['there'])
(116, ['people', 'And'])
(114, ['an'])
(113, ['Martians'])
(111, ['saw', 'through'])
...
The algorithm to count the number of words is pictured in Fig. 15. Observe the repeat-until construction.
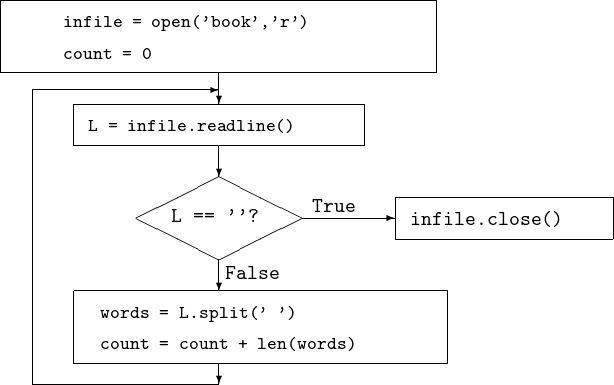
Fig. 15 Counting words in a text on file.
The code to scan a file starts below:
BOOK = "war_of_the_worlds.txt"
def word_count(name):
"""
Opens the file with name and counts the
number of words. Anything that is separated
by spaces is considered a word.
"""
file = open(name, 'r')
count = 0
while True:
line = file.readline()
if line == '':
break
words = line.split(' ')
count = count + len(words)
file.close()
return count
For the frequency count, the proper data structure is a dictionary. A dictionary in Python is
- a set of
key:valuepairs any type goes forvaluebutkeymust belong to an ordered type; - a hash table where order of elements allows for fast access.
For the frequency table in our application, we have
- type of key:
str, - type of value:
int.
An example of a key:value pair is 'the': 4076.
To introduce the use of dictionaries, consider the following interactive Python session:
>>> D = {}
>>> D['s'] = 1
>>> 's' in D
True
>>> 't' in D
False
>>> D['t'] = 2
>>> D.items()
dict_items([('s', 1), ('t', 2)])
>>> D.values()
dict_values([1, 2])
>>> D.keys()
dict_keys(['s', 't'])
Useful constructions on dictionaries are listed in Table 5.
| Python construction | what it means |
|---|---|
D = { } |
initialization |
D[<key>] = <value> |
add a key:value pair |
D[<key>] |
selection of value, given key |
<key> in D |
True if D[<key>] exists |
D.items() |
dict_items of tuples (key, value) |
D.keys() |
returns dict_keys of all keys |
D.values() |
returns dict_values of all values |
The computation of the dictionary of word frequencies is done by the function below.
def word_frequencies(name):
"""
Returns a dictionary with the frequencies
of the words occurring on file with name.
"""
file = open(name, 'r')
result = {}
while True:
line = file.readline()
if line == '':
break
words = line.split(' ')
for word in words:
if word in result:
result[word] += 1
else:
result[word] = 1
file.close()
return result
With the command freq = word_frequencies('book')
we see how many times each word occurs,
for example: freq['the'] returns 4076.
But we want to know the most frequent words,
that is: we want to query freq on the values.
We revert the dictionary:
- the keys are the frequency counts,
- because words occur more than once, the values are lists.
For example: invfreq[295] will be ['for', 'from'],
if invfreq is the reverted freq.
The computation of this dictionary where the keys are
the frequences is defined by the function frequencies_of_words.
def frequencies_of_words(freq):
"""
Reverts the keys and values of the
given dictionary freq. Because several
words may occur with the same frequency,
the values are lists of words.
"""
result = {}
for key in freq:
if freq[key] in result:
result[freq[key]].append(key)
else:
result[freq[key]] = [key]
return result
Recall that our original question was to find all
words used more than 100 times.
To answer this question, we need to sort the dictionary items.
But we cannot sort a dictionary, only lists we can sort.
Therefore we take the items in the dictionary and store
those items in a list.
The items() method on any dictionary returns
a list of tuples:
>>> L = list(D.items())
>>> L
[('s', 1), ('t', 2)]
To sort on a key, from high to low:
>>> L.sort(key=lambda i: i[1],reverse=True)
>>> L
[('t', 2), ('s', 1)]
The main program is listed below.
def main():
"""
Analysis of words in a book.
"""
cnt = word_count(BOOK)
print('words counted :', cnt)
freq = word_frequencies(BOOK)
print('number of different words :', len(freq))
invfreq = frequencies_of_words(freq)
lstfreq = list(invfreq.items())
lstfreq.sort(key=lambda e: e[0], reverse=True)
print("words used more than 100 times :")
for item in lstfreq:
if item[0] < 100:
break
print(item)
Pattern Matching¶
Manipulating text and strings is an important task. When parsing data we must ensure the entered data is correct. In search through confidential data, it is best to use program to maintain confidentiality.
For example, suppose answer contains the answers
to a yes or no question.
Acceptable yes answers are
y or yes, Y or Yes.
Testing all these four cases is tedious.
Python offers support for regular expressions,
with the module re, which is a standard library module.
Consider the following interactive session, to match short and long answers.
>>> import re
>>> (short, long) = ('y', 'Yes')
>>> re.match('y',short) != None
True
>>> re.match('y',long) != None
False
>>> re.match('y|Y',long) != None
True
>>> re.match('y|Y', long)
<_sre.SRE_Match object; span=(0, 1), match='Y'>
>>> re.match('y|Y',long).group()
'Y'
>>> re.match('y|Y',short).group()
'y'
The function match() in the re module
has the following specification:
re.match( < pattern > , < string > )
There are two possible outcomes:
- If the
stringdoes not match thepattern, thenNoneis returned. - If the
stringmatches thepattern, then a match object is returned.
For example, consider
>>> re.match('he','hello')
<_sre.SRE_Match object at 0x5cb10>
>>> re.match('hi','hello') == None
True
What can we do with the match object?
Well, we can apply the group() method, consider
>>> re.match('he','hello')
<_sre.SRE_Match object at 0x5cb10>
>>> _.group()
'he'
After a successful match, group() returns
that part of the pattern that matches the string.
The match only works from the start of the string.
>>> re.match('ell','hello') == None
True
To look for the first occurrence of the pattern
in the string, we have to use search(), as below.
>>> re.search('ell','hello')
<_sre.SRE_Match object at 0x5cb10>
>>> _.group()
'ell'
Regular Expressions¶
A regular expression defines a pattern to match a string with, introduced in Table 6.
| pattern | strings matched |
|---|---|
literal |
strings starting with literal |
re1|re2 |
strings starting with re1 or re2 |
Consider the following session.
>>> from time import ctime
>>> now = ctime()
>>> now
'Wed Jan 27 09:43:50 2016'
>>> p = ...
'\w{3}\s\w{3}\s\d{2}\s\d{2}:\d{2}:\d{2}\s\d{4}'
>>> re.match(p,now) != None
True
| pattern | strings matched |
|---|---|
\w |
any alphanumeric character, same as [A-Za-z] |
\d |
any decimal digit, same as [0-9] |
\s |
any whitespace character |
re{n} |
n occurrences of re |
We can match 0 or 1 occurrences.
Consider the following example.
We allow Ms., Mr., Mrs., with or without the . (dot).
>>> title = 'Mr?s?\.? '
There are three symbols in the string title.
?matches 0 or 1 occurrences.matches any character\.matches the dot.
Consider the following examples.
>>> re.match(title,'Ms ') != None
True
>>> re.match(title,'Ms. ') != None
True
>>> re.match(title,'Miss ') != None
False
>>> re.match(title,'Mr') != None
False
>>> re.match(title,'Mr ') != None
True
>>> re.match(title,'M ') != None
True
We can match with specific characters. A name has to start with upper case, consider
>>> name = '[A-Z][a-z]*'
>>> G = 'Guido van Rossum'
>>> re.match(name,G)
>>> _.group()
'Guido'
>>> g = 'guido'
>>> re.match(name,g) == None
True
Groups of regular expressions are designated
with parenthesis, between ( and ).
The symtax is as follows.
< pattern > = ( < group1 > ) ( < group2 > )
m = re.match( < pattern > , < string > )
if m != None: m.groups()
After a successful match, groups() returns a tuple of
those parts of the string that matched the pattern.
As an application, consider the extraction of
hours, seconds, and minutes,
using the groups() method:
>>> import re
>>> from time import ctime
>>> now = ctime()
>>> now
'Wed Jan 27 09:51:28 2016'
>>> t = now.split(' ')[3]
>>> t
'09:51:28'
>>> format = '(\d\d):(\d\d):(\d\d)'
>>> m = re.match(format, t)
>>> m.groups()
('09', '51', '28')
>>> (hours, minutes, seconds) = _
Exercises¶
- Words may contain
\nor other special symbols. Modify the code to first strip the word of special symbols and to convert to lower case before updating the dictionary. - Modify the script
wordswardict.pyto count letters instead of words. - Download of 2 different authors 2 different texts from <http://www.gutenberg.org>. Do the word frequencies tell which texts are written by the same author?
- Write a regular expression to match all words that start
with
aand end witht. - Modify
wordswardict.pyso that it prompts the user for a regular expression and then builds a frequency table for those words that match the regular expression.