Introduction to Hadoop¶
What is Hadoop?¶
We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools is to apply complex analytics to large data sets. A complementary technology is the use of cloud computing, in particular: Amazon Web Services. Assumptions for writing MapReduce applications is that one is comfortable writing Java programs; and familiar with the Unix command-line interface.
What is the value of data? Some questions are relevant only for large data sets. For example: movie preferences are inaccurate when based on just another person, but patterns can be extracted from the viewing history of millions. Big data tools enable processing on larger scale at lower cost. Additional hardware is needed to make up for latency. The notion of what is a database should be revisited. It is important to realize that one no longer needs to be among the largest corporations or government agencies to extract value from data.
The are two ways to process large data sets:
- scale-up: large and expensive computer (supercomputer). We move the same software onto larger and larger servers.
- scale-out: spread processing onto more and more machines (commodity cluster).
These two ways are subject to limiting factors. One has to deal with the complexity of concurrency in multiple CPUs; and CPUs are much faster than memory and hard disk speeds. There is a third way: Cloud computing In this third way, the provider deals with scaling problems.
The principles of Hadoop are listed below:
- All roads lead to scale-out, scale-up architectures are rarely used and scale-out is the standard in big data processing.
- Share nothing: communication and dependencies are bottlenecks, individual components should be as independent as possible to allow to proceed regardless of whether others fail.
- Expect failure: components will fail at inconvenient times. See our previous exercise on multi-component expected life span; resilient scale-up architectures require much effort.
- Smart software, dumb hardware: push smarts in the software, responsible for allocating generic hardware.
- Move processing, not data: perform processing locally on data. What gets moved through the network are program binaries and status reports, which are dwarfed in size by the actual data set.
- Build applications, not infrastructure. Instead of placing focus on data movement and processing, work on job scheduling, error handling, and coordination.
Who to thank for Hadoop? A brief history of Hadoop: Google released two academic papers describing their technology: in 2003: the google file system; and in 2004: MapReduce. The papers are available for download from <google.research.com.> Doug Cutting started implementing Google systems, as a project within the Apache open source foundation. Yahoo hired Doug Cutting in 2006 and supported Hadoop project.
From Tom White: Hadoop: The Definitive Guide, published by O’Reilly, on the name Hadoop:
The name my kid gave a stuffed yellow elephant. Short, relatively easy to spell and pronounce, meaningless, and not used elsewhere: those are my naming criteria. Kids are good at generating such.
Two main components of Hadoop are the Hadoop Distributed File System (HDFS) and MapReduce. HDFS stores very large data sets across a cluster of hosts, it is optimized for throughput instead of latency, achieving high availability through replication instead of redundancy. MapReduce is a data processing paradigm that takes a specification of input (map) and output (reduce) and applies this to the data. MapReduce integrates tightly with HDFS, running directly on HDFS nodes.
Common building blocks are
- run on commodity clusters, scale-out: can add more servers;
- have mechanisms for identifying and working around failures;
- provides services transparently, user can concentrate on problem; and
- software cluster sitting on physical server controls execution.
The Hadoop Distributed File System (HDFS) spreads the storage across nodes. Its features are thatfiles stored in blocks of 64MB (typical file system: 4-32 KB); it is optimized for throughput over latency, efficient at streaming, but poor at seek requests for many smale ones; optimized for workloads that are read-many and write-once; storage node runs process DataNode that manages blocks, coordinated by master NameNode process running on separate host; and replicates blocks on multiple nodes to handle disk failures.
MapReduce is a new technology built on fundamental concepts: functional programming languages offer map and reduce; divide and conquer breaks problem into multiple subtasks. The input data goes to a series of transformations: the developer defines the data transformations, Hadoop’s MapReduce job manages parallel execution.
Unlike relational databases the required structure data, the data is provided as a series of key-value pairs and the output of the map is another set of key-value pairs. The most important point we should not forget is: the Hadoop platform takes responsibility for every aspect of executing the processing across the data. The user is unaware of the actual size of data and cluster, the platform determines how best to utilize all the hosts.
The challenge to the user is to break the problem into the best combination of chains of map and reduce functions, where the output of one is the input of the next; and em where each chain could be applied independently to each data element, allowing for parallelism.
The common architecture of HDFS and MapReduce are software clusters: cluster of worker nodes managed by a coordinator node; master (NameNode for HDFS and JobTracker for MapReduce) monitors clusters and handles failures; processes on server (DataNode for HDFS and TaskTracker for MapReduce) perform work on physical host, receiving instructions for master and reporting status. A multi-node Hadoop cluster in an image copied from wikipedia is shown below:
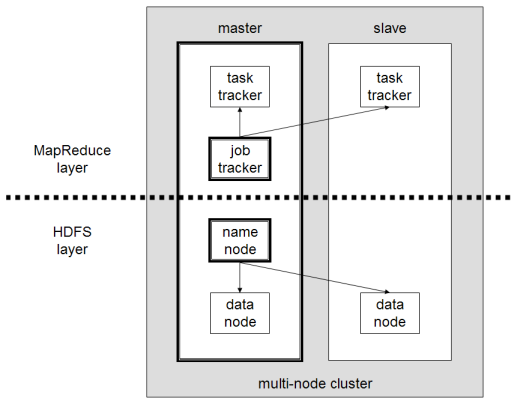
Fig. 65 A multi-node Hadoop cluster.
Strengths and weaknesses: Hadoop is flexible and scalable data processing platform; but batch processing not for real time, e.g.: serving web queries. Application by Google, in three stages.
- A web crawler retrieves updated webpage data.
- MapReduces processes the huge data set.
- The web index is then used by a fleet of MySQL servers for search requests.
Cloud computing with Amazon Web Services is another technology. Two main aspects are that it is new architecture option; and it gives a different approach to cost. Instead of running your own clusters, all you need is a credit card. This is the third way, recall the three ways:
- scale-up: supercomputer;
- scale-out: commodity cluster;
- cloud computing: the provider deals with the scaling problem.
How does cloud computing work? There are wo steps:
- The user develops software according to published guidelines or interface; and
- then deploys onto the cloud platform and allow the service to scale on demand.
The service-on-demand aspect allows to start an application on small hardware and scale up, off loading infrastructure costs to cloud provider. The major benefit is a great reduction of cost of entry for organization to launch an online service.
Amazon Web Services (AWS) is an infrastructure on demand A set of cloud computing services: EC2, S3, and EMR. Elastic Compute Cloud (EC2): a server on demand. Simple Storage Service (S3): programmatic interface to store objects. Elastic MapReduce (EMR): Hadoop in the cloud. In most impressive mode: EMR pulls data from S3, process on EC2.
Understanding MapReduce¶
We can view MapReduce as a series of key/value transformations:
map reduce
{K1, V1} --> {K2, List<V2>} -----> {K3, V3}
Two steps, three sets of key-value pairs:
- The input to the map is a series of key-value pairs,
called
K1andV1. - The output of the map (and the input to the reduce) is a series of
keys and an associated list of values
that are called
K2andV2. - The output of the reduce is another series of key-value pairs,
called
K3andV3.
The word count problem is the equivalent to hello world in Hadoop. On input is a text file. The output lists the frequency of words. Project Gutenberg (at <www.gutenberg.org>) offers many free books (mostly classics) in plain text file format. Doing a word count is a very basic data analytic, same authors will use the same patterns of words.
In solving the word count problem with MapReduce, we determine the keys and the corresponding values. Every word on the text file is a key. Its value is the count, its number of occurrences. Keys must be unique, but values need not be. Each value must be associate with a key, but a key could have no values One must be careful when defining what is a key, e.g. for the word problem do we distinguish between lower and upper case words?
A complete MapReduce Job for the word count problem:
- Input to the map:
K1/V1pairs are in the form< line number, text on the line >. The mapper takes the line and breaks it up into words. - Output of the map, input of reduce:
K2/V2pairs are in the form< word, 1 >}. - Output of reduce:
K3/V3pairs are in the form< word, count >}.
Pseudo code for the word count problem is listed below:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
some more examples¶
Distributed Grep
The map function emits a line if it matches a supplied pattern. The reduce function is an identity function that just copies the supplied intermediate data to the output.
Count of URL Access Frequency
The map function processes logs of web page requests and outputs
(URL, 1). The reduce function adds together all values for the same URL and emits a(URL, total count)pair.Reverse Web-Link Graph
The map function outputs (
target,source) pairs for each link to a target URL found in a page namedsource. The reduce function concatenates the list of all source URLs associated with a given target URL and emits the pair: (target, list (source)).Term-Vector per Host
A term vector summarizes the most important words that occur in a document or a set of documents as a list of (word, frequency) pairs. The map function emits a (
hostname,term vector) pair for each input document (where the hostname is extracted from the URL of the document). The reduce function is passed all per-document term vectors for a given host. It adds these term vectors together, throwing away infrequent terms, and then emits a final (hostname,term vector) pair.Inverted Index
The map function parses each document, and emits a sequence of (
word,document ID) pairs. The reduce function accepts all pairs for a given word, sorts the corresponding document IDs and emits a (word, list (document ID)) pair. The set of all output pairs forms a simple inverted index. It is easy to augment this computation to keep track of word positions.Distributed Sort
The map function extracts the key from each record, and emits a
key,record) pair. The reduce function emits all pairs unchanged. This computation depends on the partitioning facilities: hashing keys; and and the ordering properties: within a partition key-value pairs are processed in increasing key order.
Bibliography¶
- Luiz Barroso, Jeffrey Dean, and Urs Hoelzle. Web Search for a Planet: The Google Cluster Architecture. <research.google.com/archive/googlecluster.html>.
- Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. At <research.google.com/archive/mapreduce.html>. Appeared in OSDI‘04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, December 2004.
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google File System. At <research.google.com/archive/gfs.html>. Appeared in 19th ACM Symposium on Operating Systems Principles, Lake George, NY, October, 2003.
- Garry Turkington. Hadoop Beginner’s Guide. <www.it-ebooks.info>.
Exercises¶
- Install Hadoop on your computer and run the word count problem.
- Consider the pancake problem we have seen in Lecture 23 and formulate a solution within the MapReduce programming model.