A Massively Parallel Processor: the GPU¶
Introduction to General Purpose GPUs¶
Thanks to the industrial success of video game development graphics processors became faster than general CPUs. General Purpose Graphic Processing Units (GPGPUs) are available, capable of double floating point calculations. Accelerations by a factor of 10 with one GPGPU are not uncommon. Comparing electric power consumption is advantageous for GPGPUs.
Thanks to the popularity of the PC market, millions of GPUs are available – every PC has a GPU. This is the first time that massively parallel computing is feasible with a mass-market product. Applications such as magnetic resonance imaging (MRI) use some combination of PC and special hardware accelerators.
In five weeks, we plan to cover the following topics:
- architecture, programming models, scalable GPUs
- introduction to CUDA and data parallelism
- CUDA thread organization, synchronization
- CUDA memories, reducing memory traffic
- coalescing and applications of GPU computing
The lecture notes follow the book by David B. Kirk and Wen-mei W. Hwu: Programming Massively Parallel Processors. A Hands-on Approach. Elsevier 2010; second edition, 2013.
The site <http://gpgpu.org> is a good start for many tutorials.
What are the expected learning outcomes from the part of the course?
- We will study the design of massively parallel algorithms.
- We will understand the architecture of GPUs and the programming models to accelerate code with GPUs.
- We will use software libraries to accelerate applications.
The key questions we address are the following:
- Which problems may benefit from GPU acceleration?
- Rely on existing software or develop own code?
- How to mix MPI, multicore, and GPU?
The textbook authors use the peach metaphor: much of the application code will remain sequential; but GPUs can dramatically improve easy to parallelize code.
our equipment: hardware and software¶
Our Microway workstation has an NVIDIA GPU with the CUDA software development installed.
- NVDIA Tesla K20c general purpose graphics processing unit
- number of CUDA cores: 2,496 (13 $times$ 192)
- frequency of CUDA cores: 706MHz
- double precision floating point performance: 1.17 Tflops (peak)
- single precision floating point performance: 3.52 Tflops (peak)
- total global memory: 4800 MBytes
- CUDA programming model with
nvcccompiler.
To compare the theoretical peak performance of the K20C, consider the theoretical peak performance of the two Intel E5-2670 (2.6GHz 8 cores) CPUs in the workstation:
- 2.60 GHz \(\times\) 8 flops/cycle = 20.8 GFlops/core;
- 16 core \(\times\) 20.8 GFlops/core = 332.8 GFlops.
\(\Rightarrow\) 1170/332.8 = 3.5. One K20c is as strong as 3.5 \(\times\) 16 = 56.25 cores.
CUDA stands for Compute Unified Device Architecture, is a general purpose parallel computing architecture introduced by NVDIA.
Graphics Processors as Parallel Computers¶
In this section we compare the performance between GPUs and CPU, explaining the difference between their architectures. The performance gap between GPUs and CPUs is illustrated by two figures, taken from the NVIDIA CUDA programming guide. We compare the flops in Fig. 66 and the memory bandwidth in Fig. 67.
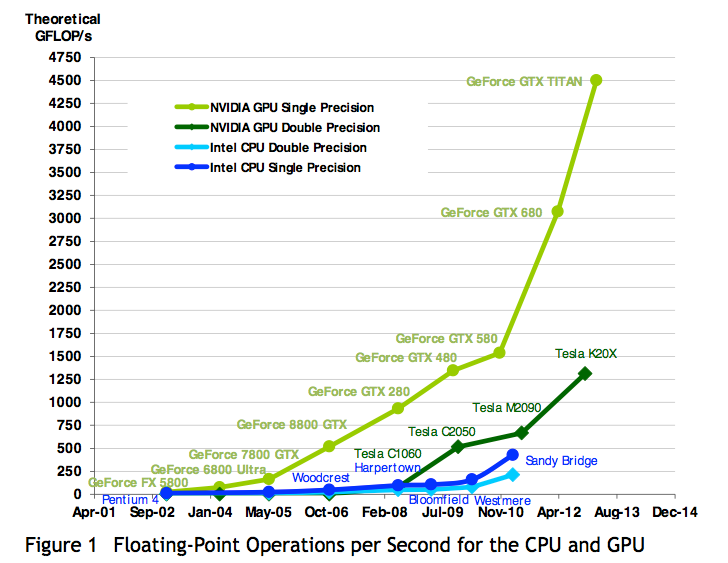
Fig. 66 Flops comparison taken from the NVIDIA programming guide.
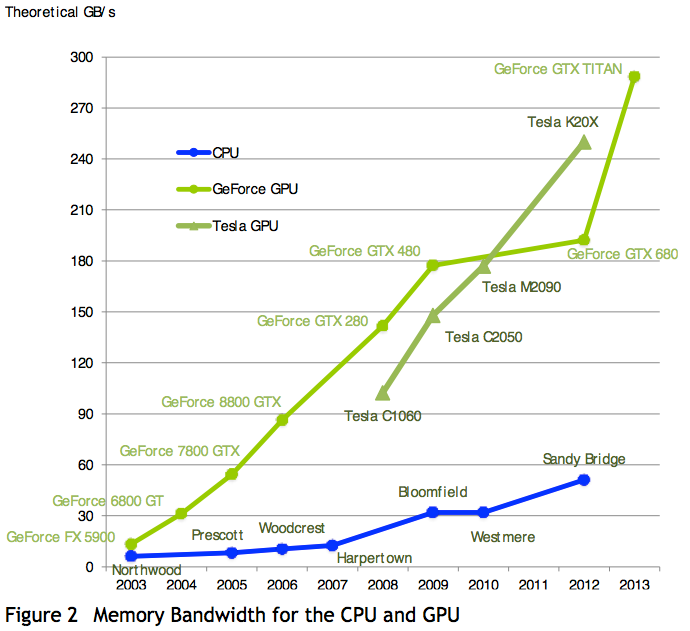
Fig. 67 Bandwidth comparision taken from the NVIDIA programming guide.
Memory bandwidth is the rate at which data can be read from/stored into memory, expressed in bytes per second. Graphics chips operate at approximately 10 times the memory bandwidth of CPUs. For our Microway station, the memory bandwidth of the CPUs is 10.66GB/s. For the NVDIA Tesla K20c the memory bandwidth is 143GB/s. Straightforward parallel implementations on GPGPUs often achieve directly a speedup of 10, saturating the memory bandwidth.
CPU and GPU design¶
The main distinction between the CPU and GPU design is as follows:
- CPU: multicore processors have large cores and large caches using control for optimal serial performance.
- GPU: optimizing execution throughput of massive number of threads with small caches and minimized control units.
The distinction is illustrated in Fig. 68.
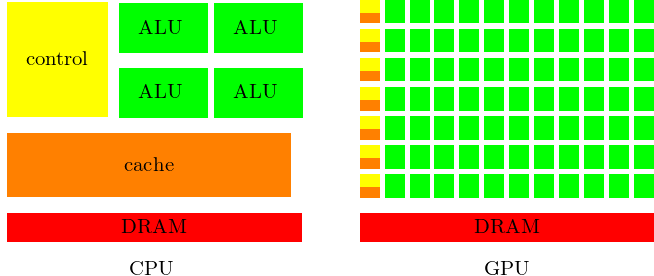
Fig. 68 Distinction between the design of a CPU and a GPU.
The architecture of a modern GPU is summarized in the following items:
- A CUDA-capable GPU is organized into an array of highly threaded Streaming Multiprocessors (SMs).
- Each SM has a number of Streaming Processors (SPs) that share control logic and an instruction cache.
- Global memory of a GPU consists of multiple gigabytes of Graphic Double Data Rate (GDDR) DRAM.
- Higher bandwidth makes up for longer latency.
- The growing size of global memory allows to keep data longer in global memory, with only occasional transfers to the CPU.
- A good application runs 10,000 threads simultaneously.
A concrete example of the GPU architecture is in Fig. 69.

Fig. 69 A concrete example of the GPU architecture.
begin{frame}{our NVIDIA Tesla K20C GPU}
Our K20C Graphics card has
- 13 streaming multiprocessors (SM),
- each SM has 192 streaming processors (SP),
- \(13 \times 192 = 2496\) cores.
Streaming multiprocessors support up to 2,048 threads. The multiprocessor creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps. Unlike CPU cores, threads are executed in order and there is no branch prediction, although instructions are pipelined.
programming models and data parallelism¶
According to David Kirk and Wen-mei Hwu (page 14): Developers who are experienced with MPI and OpenMP will find CUDA easy to learn. CUDA (Compute Unified Device Architecture) is a programming model that focuses on data parallelism.
Data parallelism involves
- huge amounts of data on which
- the arithmetical operations are applied in parallel.
With MPI we applied the SPMD (Single Program Multiple Data) model. With GPGPU, the architecture is SIMT = Single Instruction Multiple Thread. An example with large amount of data parallelism is matrix-matrix multiplication in large dimensions. Available Software Development Tools (SDK), e.g.: BLAS, FFT are available for download at <http://www.nvidia.com>.
Alternatives to CUDA are
- OpenCL (chapter 14) for heterogeneous computing;
- OpenACC (chapter 15) uses directives like OpenMP;
- C++ Accelerated Massive Parallelism (chapter 18).
Extensions to CUDA are
- Thrust: productivity-oriented library for CUDA (chapter~16);
- CUDA FORTRAN (chapter 17);
- MPI/CUDA (chapter 19).
Bibliography¶
- NVIDIA CUDA Programming Guide. Available at <http://developer.nvdia.com>.
- Victor W. Lee et al: Debunking the 100X GPU vs. CPU Myth: An Evaluation of Throughput Computing on CPU and GPU. In Proceedings of the 37th annual International Symposium on Computer Architecture (ISCA‘10), ACM 2010.
- W.W. Hwu (editor). GPU Computing Gems: Emerald Edition. Morgan Kaufmann, 2011.
Exercises¶
- Visit <http://gpgpu.org>.