Concurrent Kernels and Multiple GPUs¶
Page Locked Host Memory¶
In contrast to regular pageable host memory, the runtime provides functions to allocate (and free) page locked memory. Another name for memory that is page locked is pinned.
Using page locked memory has several benefits:
- Copies between page locked memory and device memory can be performed concurrently with kernel execution.
- Page locked host memory can be mapped into the address space of the device, eliminating the need to copy, we say zero copy.
- Bandwidth between page locked host memory and device may be higher.
Page locked host memory is a scarce resource. The NVIDIA CUDA Best Practices Guide assigns a low priority to zero-copy operations (i.e.: mapping host memory to the device).
To allocate page locked memory, we use cudaHostAlloc()
and to free the memory, we call cudaFreeHost().
To map host memory on the device:
- The flag
cudaHostAllocMappedmust be given tocudaHostAlloc()when allocating host memory. - A call to
cudaHostGetDevicePointer()maps the host memory to the device.
If all goes well, then no copies from host to device memory and from device to host memory are needed.
Not all devices support pinned memory, it is recommended
practice to check the device properties
(see the deviceQuery in the SDK).
Next we illustrate how a programmer may use pinned memory with a simple program. A run of this program is below.
$ /tmp/pinnedmemoryuse
Tesla K20c supports mapping host memory.
The error code of cudeHostAlloc : 0
Squaring 32 numbers 1 2 3 4 5 6 7 8 9 10 11 12 13 \
14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32...
The fail code of cudaHostGetDevicePointer : 0
After squaring 32 numbers 1 4 9 16 25 36 49 64 81 \
100 121 144 169 196 225 256 289 324 361 400 441 484 \
529 576 625 676 729 784 841 900 961 1024...
$
The execution of the program is defined by the code in
pinnedmemoryuse.cu, listed below.
First we check whether the devide supports pinned memory.
#include <stdio.h>
int checkDeviceProp ( cudaDeviceProp p );
/*
* Returns 0 if the device does not support mapping
* host memory, returns 1 otherwise. */
int checkDeviceProp ( cudaDeviceProp p )
{
int support = p.canMapHostMemory;
if(support == 0)
printf("%s does not support mapping host memory.\n",
p.name);
else
printf("%s supports mapping host memory.\n",p.name);
return support;
}
To illustrate pinned memory, we use the following simple kernel.
__global__ void Square ( float *x )
/*
* A kernel where the i-th thread squares x[i]
* and stores the result in x[i]. */
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
x[i] = x[i]*x[i];
}
This kernel is launched in the main program below.
void square_with_pinned_memory ( int n );
/*
* Illustrates the use of pinned memory to square
* a sequence of n numbers. */
int main ( int argc, char* argv[] )
{
cudaDeviceProp dev;
cudaGetDeviceProperties(&dev,0);
int success = checkDeviceProp(dev);
if(success != 0)
square_with_pinned_memory(32);
return 0;
}
The function which allocates the pinned memory is below.
void square_with_pinned_memory ( int n )
{
float *xhost;
size_t sz = n*sizeof(float);
int error = cudaHostAlloc((void**)&xhost,
sz,cudaHostAllocMapped);
printf("\nThe error code of cudeHostAlloc : %d\n",
error);
for(int i=0; i<n; i++) xhost[i] = (float) (i+1);
printf("\nSquaring %d numbers",n);
for(int i=0; i<n; i++) printf(" %d",(int) xhost[i]);
printf("...\n\n");
// mapping host memory
float *xdevice;
int fail = cudaHostGetDevicePointer
((void**)&xdevice,(void*)xhost,0);
printf("\nThe fail code of cudaHostGetDevicePointer : \
%d\n",fail);
Square<<<1,n>>>(xdevice);
cudaDeviceSynchronize();
printf("\nAfter squaring %d numbers",n);
for(int i=0; i<n; i++) printf(" %d",(int) xhost[i]);
printf("...\n\n");
cudaFreeHost(xhost);
}
Concurrent Kernels¶
The Fermi architecture supports the simultaneous execution of kernels. The benefits of this concurrency are the following.
- Simultaneous execution of small kernels utilize whole GPU.
- Overlapping kernel execution with device to host memory copy.
A stream is a sequence of commands that execute in order. Different streams may execute concurrently. The maximum number of kernel launches that a device can execute concurrently is four.
That the GPU may be fully utilized is illustrated in Fig. 123.
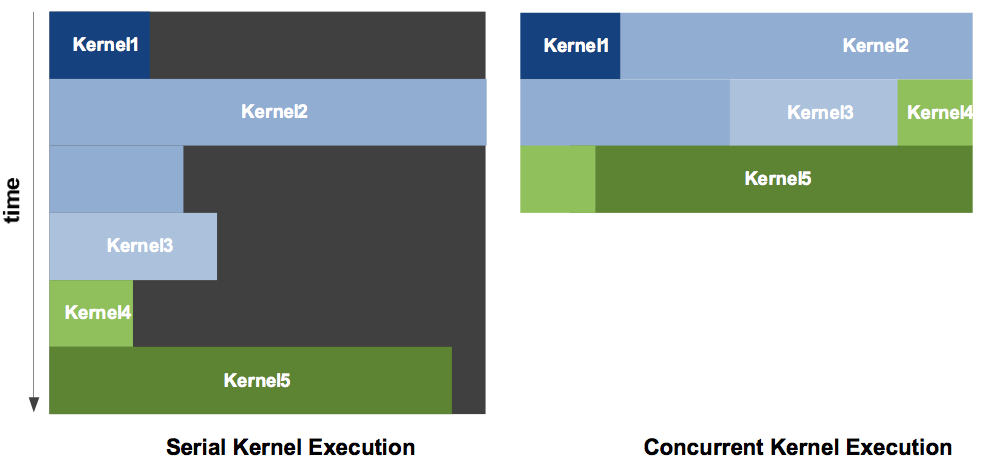
Fig. 123 Concurrent kernel execution, taken from the NVIDIA Fermi Compute Architecture Whitepaper.
The overlapping of execution of kernels with memory copies is illustrated in Fig. 124.
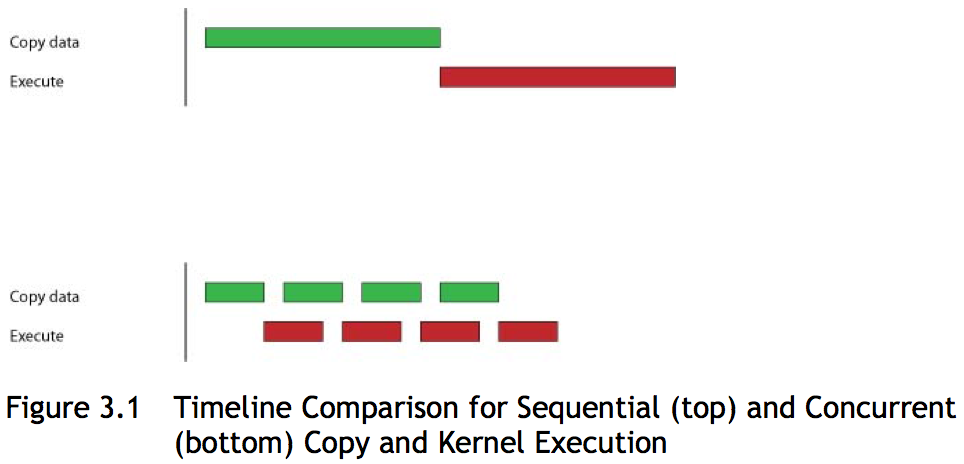
Fig. 124 Concurrent copy and kernel execution with 4 streams, taken from the NVIDIA CUDA Best Practices Guide.
To illustrate the use of streams with actual code, we consider a simple kernel to square a sequence of numbers. Its execution happens as shown below.
$ /tmp/concurrent
Tesla K20c supports concurrent kernels
compute capability : 3.5
number of multiprocessors : 13
Launching 4 kernels on 16 numbers 1 2 3 4 5 6 7 8 9 10 \
11 12 13 14 15 16...
the 16 squared numbers are 1 4 9 16 25 36 49 64 81 100 \
121 144 169 196 225 256
$
The simple kernel is defined by the function Square,
listed below.
__global__ void Square ( float *x, float *y )
/*
* A kernel where the i-th thread squares x[i]
* and stores the result in y[i]. */
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
y[i] = x[i]*x[i];
}
Before we launch this kernel, we want to check if our GPU supports concurrency. This check is done by the following function.
int checkDeviceProp ( cudaDeviceProp p )
{
int support = p.concurrentKernels;
if(support == 0)
printf("%s does not support concurrent kernels\n",
p.name);
else
printf("%s supports concurrent kernels\n",p.name);
printf(" compute capability : %d.%d \n",
p.major,p.minor);
printf(" number of multiprocessors : %d \n",
p.multiProcessorCount);
return support;
}
Then the main program follows.
void launchKernels ( void );
/*
* Launches concurrent kernels on arrays of floats. */
int main ( int argc, char* argv[] )
{
cudaDeviceProp dev;
cudaGetDeviceProperties(&dev,0);
int success = checkDeviceProp(dev);
if(success != 0) launchKernels();
return 0;
}
The memory allocation and the asynchronous kernel execution is defined in the code below.
void launchKernels ( void )
{
const int nbstreams = 4;
const int chunk = 4;
const int nbdata = chunk*nbstreams;
float *xhost;
size_t sz = nbdata*sizeof(float);
// memory allocation
cudaMallocHost((void**)&xhost,sz);
for(int i=0; i<nbdata; i++) xhost[i] = (float) (i+1);
printf("\nLaunching %d kernels on %d numbers",
nbstreams,nbdata);
for(int i=0; i<nbdata; i++)
printf(" %d",(int) xhost[i]);
printf("...\n\n");
float *xdevice; cudaMalloc((void**)&xdevice,sz);
float *ydevice; cudaMalloc((void**)&ydevice,sz);
// asynchronous execution
cudaStream_t s[nbstreams];
for(int i=0; i<nbstreams; i++) cudaStreamCreate(&s[i]);
for(int i=0; i<nbstreams; i++)
cudaMemcpyAsync
(&xdevice[i*chunk],&xhost[i*chunk],
sz/nbstreams,cudaMemcpyHostToDevice,s[i]);
for(int i=0; i<nbstreams; i++)
Square<<<1,chunk,0,s[i]>>>
(&xdevice[i*chunk],&ydevice[i*chunk]);
for(int i=0; i<nbstreams; i++)
cudaMemcpyAsync
(&xhost[i*chunk],&ydevice[i*chunk],
sz/nbstreams,cudaMemcpyDeviceToHost,s[i]);
cudaDeviceSynchronize();
printf("the %d squared numbers are",nbdata);
for(int i=0; i<nbdata; i++)
printf(" %d",(int) xhost[i]);
printf("\n");
for(int i=0; i<nbstreams; i++) cudaStreamDestroy(s[i]);
cudaFreeHost(xhost);
cudaFree(xdevice); cudaFree(ydevice);
}
Using Multiple GPUs¶
Before we can use multiple GPUs, it is good to count how many devices are available. A run to enumerate the available devices is below.
$ /tmp/count_devices
number of devices : 3
graphics card 0 :
name : Tesla K20c
number of multiprocessors : 13
graphics card 1 :
name : GeForce GT 620
number of multiprocessors : 2
graphics card 2 :
name : Tesla K20c
number of multiprocessors : 13
$
The CUDA program to count the devices is listed next.
The instructions are based on the deviceQuery.cpp
of the GPU Computing SDK.
#include <stdio.h>
void printDeviceProp ( cudaDeviceProp p )
/*
* prints some device properties */
{
printf(" name : %s \n",p.name);
printf(" number of multiprocessors : %d \n",
p.multiProcessorCount);
}
int main ( int argc, char* argv[] )
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
printf("number of devices : %d\n",deviceCount);
for(int d = 0; d < deviceCount; d++)
{
cudaDeviceProp dev;
cudaGetDeviceProperties(&dev,d);
printf("graphics card %d :\n",d);
printDeviceProp(dev);
}
return 0;
}
Chapter 8 of the NVIDIA CUDA Best Practices Guide describes multi-GPU programming.
To work with p GPUs concurrently, the CPU can use
- p lightweight threads (Pthreads, OpenMP, etc); or
- p heavyweight threads (or processes) with MPI.
The command to select a GPU is cudaSetDevice().
All inter-GPU communication happens through the host.
See the simpleMultiGPU of the GPU Computing SDK.