Neural Networks¶
We look at neural networks from the perspective of applied mathematics.
Definitions¶
In Fig. 69 is a schematic example of a neuron.
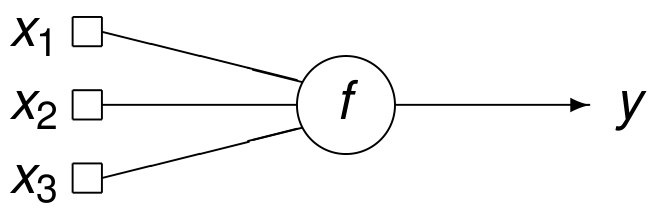
Fig. 69 A schematic of a neuron with three inputs and one output.¶
Two concrete examples of the function f are
and
An example of a neural network is defined as
where
\(\bf x\) is the input vector, of \(n\) inputs, or variables, and
\(\bf w\) is the vector of \((n+1)N_c + N_c + 1\) parameters, or weights.
The network shown in Fig. 70
has three inputs with one bias \(x_0 = 1\),
has three hidden neurons, and
one linear output neuron.
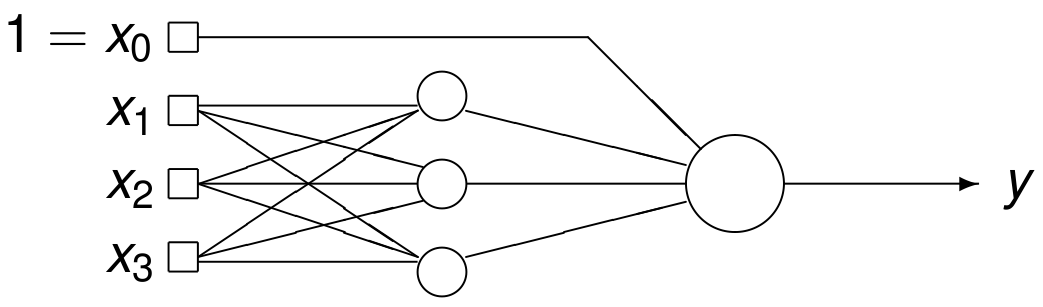
Fig. 70 An example of a neural network.¶
Two categories of training are considered:
supervised training: we know the nonlinear function analytically, or numerical values of the function are known.
unsupervised training: no supervision.
The training of a neural network can be viewed as a function approximation problem, where we keep in mind the following two properties.
Nonlinear in their parameters, neural networks are universal approximators.
The most parsimonious model has the smallest number of parameters.
An Artificial Neural Network¶
The training of a neural network will be illustrated via the processing of a collection of labeled points, shown in Fig. 71. We could interpret the labels of the points as the outcome of a probe for oil. With the neural network we would like to predict the size of the oil field, or the location for where to drill next.
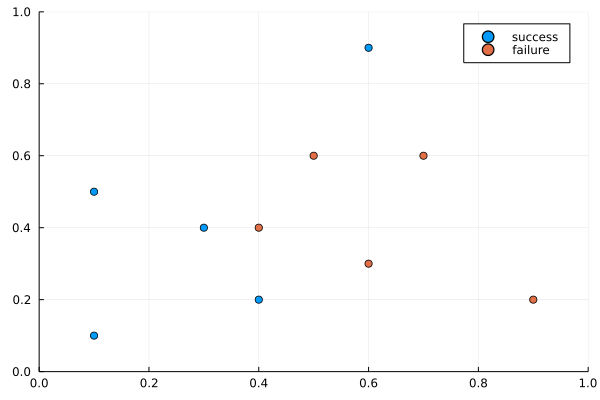
Fig. 71 A collection of labeled points.¶
The coordinates of the points are given in two vectors:
x1 = [0.1,0.3,0.1,0.6,0.4,0.6,0.5,0.9,0.4,0.7]
x2 = [0.1,0.4,0.5,0.9,0.2,0.3,0.6,0.2,0.4,0.6]
and their labels are defined as
y = [ones(1,5) zeros(1,5); zeros(1,5) ones(1,5)]
2x10 Matrix{Float64}:
1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0
The problem can then be formulated as follows. Find a function \(F\), so \(y = F(z_1, z_2)\), for a point \((z_1, z_2)\). To solve this problem, we use sigmoid functions. The sigmoid function is
and it can be viewed as a smoothed version of a step function, shown in Fig. 72.
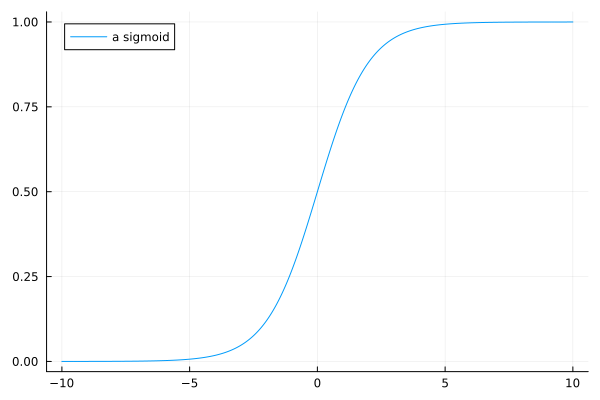
Fig. 72 The sigmoid function \(\sigma(x) = 1/(1 + e^{-x})\).¶
A scaled and shifted sigmoid function \(\sigma(3(x-5))\) is shown in Fig. 73.
Fig. 73 The scaled and shifted sigmoid \(\sigma(3(x-5))\).¶
A Julia function for \(\sigma(W x + b)\) is listed below:
"""
function activate(x,W,b)
evaluates the sigmoid function at x,
with weight matrix W and bias vector b.
"""
function activate(x,W,b)
dim = size(W,1)
y = zeros(dim)
argexp = -(W*x + b)
for i=1:dim
y[i] = 1.0/(1.0 + exp(argexp[i]))
end
return y
end
The dimensions of the variables x, W, and b
are as follows: if \(\mbox{x} \in {\mathbb R}^n\),
\(\mbox{W} \in {\mathbb R}^{m \times n}\),
\(\mbox{b} \in {\mathbb R}^m\),
then \(\mbox{y} \in {\mathbb R}^m\).
The Julia function implements a neural network as
function F(x, W2, W3, W4, b2, b3, b4)
a2 = activate(x, W2, b2)
a3 = activate(a2, W3, b3)
a4 = activate(a3, W4, b4)
return a4
end
and it computes
which can be represented as in Fig. 74.
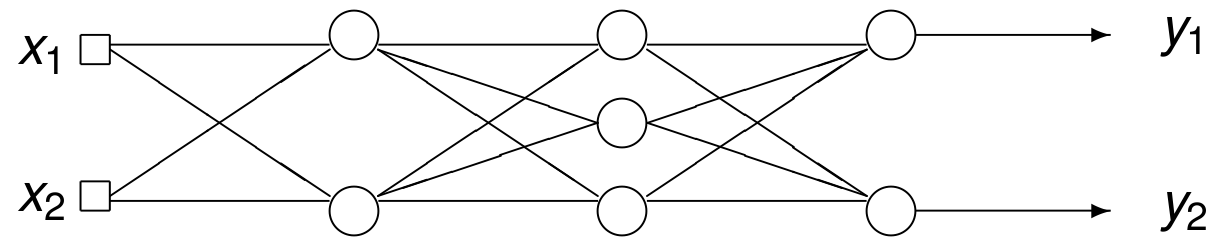
Fig. 74 The layers in an artificial neural network.¶
The weights and bias vectors in this neural network define the function
which produces labels for each point. The cost function is
The first exercise asks to count the number of parameters in the neural network defined by the function \(F\).
The problem of constructing the neural network is now reduced to minimizing the cost function. For this optimization problem, we consider Taylor series and the gradient vector. Assume the current vector is \(p = (p_1, p_2, \ldots, p_N)\).
Consider the Taylor series of the cost function at \(p\):
Denoting the gradient vector
and ignoring the \(O(\| \Delta p \|^2)\) term:
Minimizing the cost function is the objective. In an iterative method we replace \(p\) by \(p + \Delta p\), choosing \(\Delta p\) that makes \(\displaystyle \left( \vphantom{\frac{1}{2}} \nabla \mbox{Cost}(p) \right)^T \Delta p\) as negative as possible. By application of the Cauchy-Schwartz inequality:
Therefore, choose \(\Delta p\) in the direction of \(-\nabla \mbox{Cost}(p)\). Update \(p\) as \(p = p - \eta \nabla \mbox{Cost}(p)\), where the step size \(\eta\) is called the learning rate. As we have a large number of parameters and many training points, the computation of the gradient vector at each step is too costly. Instead, take one single, randomly chosen training point, and evaluate the gradient at that point. This gives rise to the stochastic gradient method.
To run the stochastic gradient method, we need to evaluate the derivatives efficiently. Let \(a^{(1)} = x\), then the network returns \(a^{(L)}\), where
Let \(C\) be the cost, define \(\displaystyle \delta_j^{(\ell)} = \frac{\partial C}{\partial z_j^{(\ell)}}\) as the error of neuron \(j\) at layer \(\ell\).
By the chain rule, we have (with \(\circ\) as the componentwise product):
Sigmoids have convenient derivatives: \(\sigma'(x) = \sigma(x) ( 1 - \sigma(x))\).
The formulas lead to the following algorithm:
The forward pass evaluates \(a^{(1)}, z^{(2)}, a^{(2)}, z^{(3)}, \ldots, a^{(L)}\).
The backward pass evaluates \(\delta^{(L)}, \delta^{(L-1)}, \ldots, \delta^{(2)}\).
This way of computing gradients is back propagation.
The Julia code to train the network is listed below:
eta = 0.05
Niter = 1000000
for counter = 1:Niter
k = rand((1:10), 1)[1]
x = [x1[k], x2[k]]
# Forward pass
a2 = activate(x,W2,b2)
a3 = activate(a2,W3,b3)
a4 = activate(a3,W4,b4)
# Backward pass
delta4 = a4.*(ones(length(a4))-a4).*(a4-y[:,k])
delta3 = a3.*(ones(length(a3))-a3).*(W4'*delta4)
delta2 = a2.*(ones(length(a2))-a2).*(W3'*delta3)
# Gradient step
W2 = W2 - eta*delta2*x'
W3 = W3 - eta*delta3*a2'
W4 = W4 - eta*delta4*a3'
b2 = b2 - eta*delta2
b3 = b3 - eta*delta3
b4 = b4 - eta*delta4
end
The output of
Z = [[x1[k], x2[k]] for k=1:10]
Y = [F(z, W2, W3, W4, b2, b3, b4) for z in Z]
is
10-element Vector{Vector{Float64}}:
[0.9914991960849379, 0.008456961045118156]
[0.9938902272050594, 0.006075750247468293]
[0.998360435186392, 0.001628134278139295]
[0.9865419031464729, 0.01338759273828821]
[0.9737963089611226, 0.02615530711128986]
[0.013028283269915059, 0.9869736384774328]
[0.016354675508034607, 0.9837066212812329]
[0.0005627461156236613, 0.9994383300176262]
[0.02106910309704885, 0.979014892476464]
[0.0012977070814389772, 0.9987047112752311]
The result of evaluating \(F(x_1, x_2)\) over \([0,1] \times [0,1]\) is shown in Fig. 75.
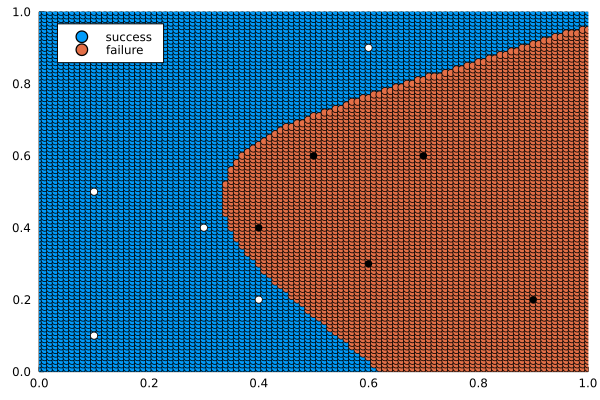
Fig. 75 Evaluating the trained neural network over \([0,1] \times [0,1]\).¶
The white and black dots in Fig. 75 are the ten given points.
Exercises¶
How many parameters are in the neural network defined by the function \(F(x)\)? Justify your answer.
Examine the computational cost to evaluate \(\nabla \mbox{Cost}(p)\) of our \(\displaystyle F(x) = \sigma(~\!\mbox{W4 }\! \sigma(~\!\mbox{W3 }\! \sigma(~\!\mbox{W2 }\!\mbox{x} + \mbox{b2}) + \mbox{b3}) + \mbox{b4})\).
How fast did the stochastic gradient method converge?
Write a function to evaluate \(\mbox{Cost}(p)\).
Call the function in the code to train the network, at each step, store the value of the cost function.
Make a plot of the cost over all steps in the code.
Bibliography¶
Gerard Dreyfus: Neural Networks. Methodology and Applications. Springer-Verlag 2005.
Catherine F. Higham and Desmond J. Higham: Deep Learning: An Introduction for Applied Mathematicians. SIAM Review, Vol. 61, No. 4, pages 860-891, 2019.