Device Memories and Matrix Multiplication¶
The performance of our first, straightforward definition of an accelerated matrix matrix multiplication was disappointing. Tiling the matrices and paying attention to the memory hierarchies dramatically improves the performance.
Device Memories¶
Before we launch a kernel, we have to allocate memory on the device, and to transfer data from the host to the device. By default, memory on the device is global memory. In addition to global memory, we distinguish between
registers for storing local variables,
shared memory for all threads in a block,
constant memory for all blocks on a grid.
The importance of understanding different memories is in the calculation of the expected performance level of kernel code.
If the CGMA ratio is 1.0, then the memory clock rate determines the upper limit for the performance. This corresponds to the roofline model discussed earlier, see Fig. 43 and Fig. 44. While memory bandwidth on a GPU is superior to that of a CPU, we will miss the theoretical peak performance by a factor of ten.
The different types of memory are schematically presented in Fig. 64.
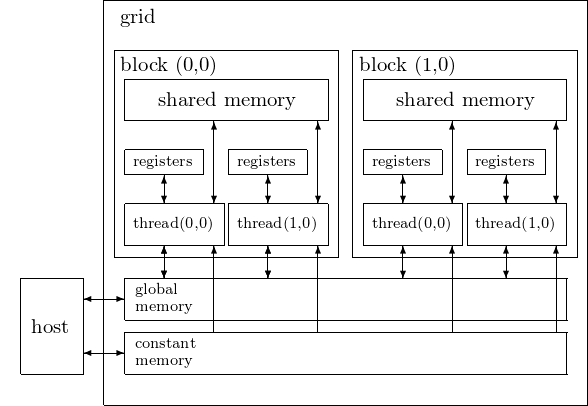
Fig. 64 The CUDA device memory types.¶
Registers are allocated to individual threads. Each thread can access only its own registers. A kernel function typically uses registers to hold frequently accessed variables that are private to each thread.
Number of 32-bit registers available per block:
8,192 on the GeForce 9400M,
32,768 on the Tesla C2050/C2070,
65,536 on the K20C, P100, V100, and A100.
A typical CUDA kernel may launch thousands of threads. However, having too many local variables in a kernel function may prevent all blocks from running in parallel.
Like registers, shared memory is an on-chip memory. Variables residing in registers and shared memory can be accessed at very high speed in a highly parallel manner. Unlike registers, which are private to each thread, all threads in the same block have access to shared memory.
Amount of shared memory per block:
16,384 byes on the GeForce 9400M,
49,152 bytes on the Tesla C2050/C2070,
49,152 bytes on the K20c, P100, V100, and A100.
The constant memory supports short-latency, high-bandwidth, read-only access by the device when all threads simultaneously access the same location.
The GeForce 9400M has 65,536 bytes of constant memory, the total amount of global memory is 254 MBytes.
The Tesla C2050/C2070 has 65,536 bytes of constant memory, the total amount of global memory is 2,687 MBytes, with 786,432 bytes of L2 Cache.
The K20c has 65,536 bytes of constant memory, the total amount of global memory is 4,800 MBytes (5,032,706,048 bytes) with 1,310,720 bytes of L2 Cache.
The constant memory remained the same for the P100, V100, and A100, but the global memory and L2 cache increased, see the summary in Table 16.
GPU type |
constant |
global |
L2 cache |
|---|---|---|---|
GeForce 9400 M |
65,536 b |
254 Mb |
|
Tesla C2050 |
65,536 b |
2,687 Mb |
786,432 b |
Kepler K20C |
65,536 b |
4,800 Mb |
1,310,720 b |
Pascal P100 |
65,536 b |
16,376 Mb |
4,194,304 b |
Volta V100 |
65,536 b |
32,505 Mb |
6,291,456 b |
Ampere A100 |
65,536 b |
81,038 Mb |
41,943,040 b |
The relationshiop between thread organization and different types of device memories is shown in Fig. 65, copied from the NVIDIA Whitepaper on Kepler GK110.
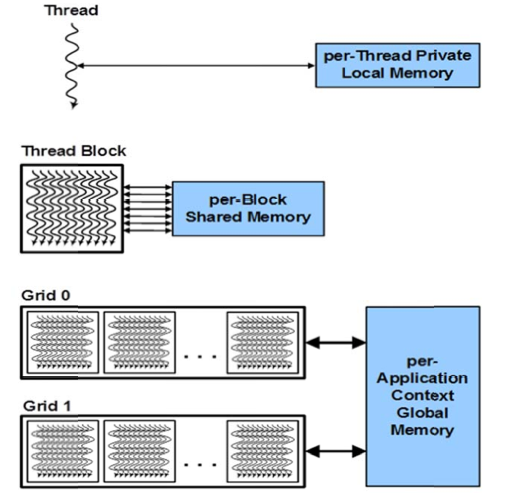
Fig. 65 Registers, shared, and global memory per thread, thread block, and grid.¶
Each variable is stored in a particular type of memory, has a scope and a lifetime.
Scope is the range of threads that can access the variable. If the scope of a variable is a single thread, then a private version of that variable exists for every single thread. Each thread can access only its private version of the variable.
Lifetime specifies the portion of the duration of the program execution when the variable is available for use. If a variable is declared in the kernel function body, then that variable is available for use only by the code of the kernel. If the kernel is invoked several times, then the contents of that variable will not be maintained across these invocations.
We distinguish between five different variable declarations, based on their memory location, scope, and lifetime, summarized in Table 17.
variable declaration |
memory |
scope |
lifetime |
|---|---|---|---|
atomic variables |
register |
thread |
kernel |
array variables |
local |
thread |
kernel |
|
shared |
block |
kernel |
|
global |
grid |
program |
|
constant |
grid |
program |
The __device__ in front of __shared__ is optional.
Matrix Multiplication¶
In an application of tiling, let us examine the CGMA ratio. In our simple implementation of the matrix-matrix multiplication \(C = A \cdot B\), we have the statement
C[i] += (*(pA++))*(*pB);
where
Cis a float array; andpAandpBare pointers to elements in a float array.
For the statement above, the CGMA ratio is 2/3:
for one addition and one multiplication,
we have three memory accesses.
To improve the CGMA ratio, we apply tiling. For \(A \in {\mathbb R}^{n \times m}\) and \(B \in {\mathbb R}^{m \times p}\), the product \(C = A \cdot B \in {\mathbb R}^{n \times p}\). Assume that \(n\), \(m\), and \(p\) are multiples of some \(w\), e.g.: \(w = 8\). We compute \(C\) in tiles of size \(w \times w\):
Every block computes one tile of \(C\).
All threads in one block operate on submatrices:
\[C_{i,j} = \sum_{k=1}^{m/w} A_{i,k} \cdot B_{k,j}.\]The submatrices \(A_{i,k}\) and \(B_{k,j}\) are loaded from global memory into shared memory of the block.
The tiling of matrix multiplication as it relates to shared memory is shown in Fig. 66.
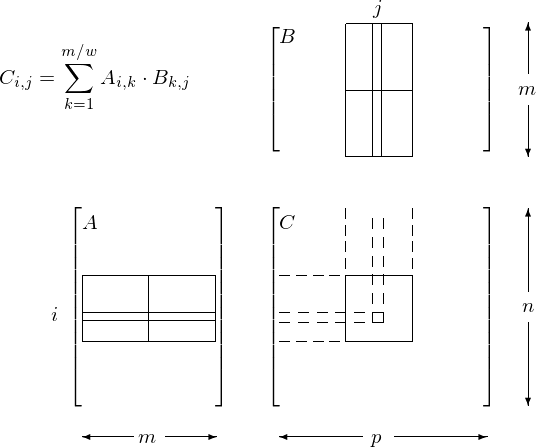
Fig. 66 Tiled matrix multiplication and shared memory.¶
The GPU computing SDK contains as one of the examples matrixMul
and this matrixMul is explained in great detail in the
CUDA programming guide.
We run it on the GeForce 9400M, the Tesla C2050/C2070,
and the K20C, P100, V100, A100.
A session on the A100 is below:
$ /usr/local/cuda/samples/bin/x86_64/linux/release/matrixMul
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "Ampere" with compute capability 8.0
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 4303.49 GFlop/s, Time= 0.030 msec, Size= 131072000 Ops,
WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements.
Results may vary when GPU Boost is enabled.
Observe the 4.303 TFlop/s performance. The theoretical peak performance (with GPU Boost) is 78 TFlop/s (half), 19.5 TFlop/s (single), 9.7 TFlop/s (double). The performance improves with CUBLAS, the CUDA libraries for the Basic Linear Algebra Software. A session on the A100 with CUBLAS is below:
$ /usr/local/cuda/samples/bin/x86_64/linux/release/matrixMulCUBLAS
[Matrix Multiply CUBLAS] - Starting...
GPU Device 0: "Ampere" with compute capability 8.0
GPU Device 0: "NVIDIA A100 80GB PCIe" with compute capability 8.0
MatrixA(640,480), MatrixB(480,320), MatrixC(640,320)
Computing result using CUBLAS...done.
Performance= 11076.92 GFlop/s, Time= 0.018 msec, Size= 196608000 Ops
Computing result using host CPU...done.
Comparing CUBLAS Matrix Multiply with CPU results: PASS
NOTE: The CUDA Samples are not meant for performance measurements.
Results may vary when GPU Boost is enabled.
Observe the 11.076 TFlop/s performance. For single floats, the theoretical peak precision is 17.6 TFlop/s, or 19.5 TFlop/s with GPU Boost.
The comparison of several generations of NVIDIA GPUs is
summarized in table Table 18.
The units in Table 18 are GFlop/s
for the performance of matrixMul and CUBLAS,
but then TFlop/s for the peak performance in the last column.
GPU |
matrixMul |
CUBLAS |
peak |
|---|---|---|---|
K20C |
264 |
1,171 |
3.5 |
P100 |
1,909 |
3,089 |
9.3 |
V100 |
2,974 |
7,146 |
14.8 |
A100 |
4,303 |
11,076 |
19.5 |
The code of the kernel of matrixMul is listed next.
template <int BLOCK_SIZE> __global__ void
matrixMul( float* C, float* A, float* B, int wA, int wB)
{
int bx = blockIdx.x; // Block index
int by = blockIdx.y;
int tx = threadIdx.x; // Thread index
int ty = threadIdx.y;
// Index of the first sub-matrix of A processed by the block
int aBegin = wA * BLOCK_SIZE * by;
// Index of the last sub-matrix of A processed by the block
int aEnd = aBegin + wA - 1;
// Step size used to iterate through the sub-matrices of A
int aStep = BLOCK_SIZE;
// Index of the first sub-matrix of B processed by the block
int bBegin = BLOCK_SIZE * bx;
// Step size used to iterate through the sub-matrices of B
int bStep = BLOCK_SIZE * wB;
// Csub is used to store the element of the block sub-matrix
// that is computed by the thread
float Csub = 0;
// Loop over all the sub-matrices of A and B
// required to compute the block sub-matrix
for (int a = aBegin, b = bBegin;
a <= aEnd;
a += aStep, b += bStep) {
// Declaration of the shared memory array As used to
// store the sub-matrix of A
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
// Declaration of the shared memory array Bs used to
// store the sub-matrix of B
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load the matrices from device memory
// to shared memory; each thread loads
// one element of each matrix
AS(ty, tx) = A[a + wA * ty + tx];
BS(ty, tx) = B[b + wB * ty + tx];
// Synchronize to make sure the matrices are loaded
__syncthreads();
// Multiply the two matrices together;
// each thread computes one element
// of the block sub-matrix
#pragma unroll
for (int k = 0; k < BLOCK_SIZE; ++k)
Csub += AS(ty, k) * BS(k, tx);
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write the block sub-matrix to device memory;
// each thread writes one element
int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx;
C[c + wB * ty + tx] = Csub;
}
The emphasis in this lecture is on
the use of device memories; and
data organization (tiling) and transfer.
In the next lecture we will come back to this code, and cover thread scheduling
the use of
blockIdx; andthread synchronization.
Bibliography¶
Vasily Volkov and James W. Demmel:
Benchmarking GPUs to tune dense linear algebra.
In Proceedings of the 2008 ACM/IEEE conference on Supercomputing, IEEE Press, 2008. Article No. 31.
Exercises¶
Compile the
matrixMulof the GPU Computing SDK on your laptop and desktop and run the program.Consider the matrix multiplication code of last lecture and compute the CGMA ratio.
Adjust the code for matrix multiplication we discussed last time to use shared memory.